
I am a business analyst turned data scientist who is passionate about solving business problems by data-driven approaches.
I am a business analyst turned data scientist who is passionate about solving business problems by data-driven approaches.
SOTA mathematical backend for deep learning

EchoAI Package is created to provide an implementation of the most promising mathematical algorithms, which are missing in the most popular deep learning libraries, such as PyTorch, Keras and TensorFlow.
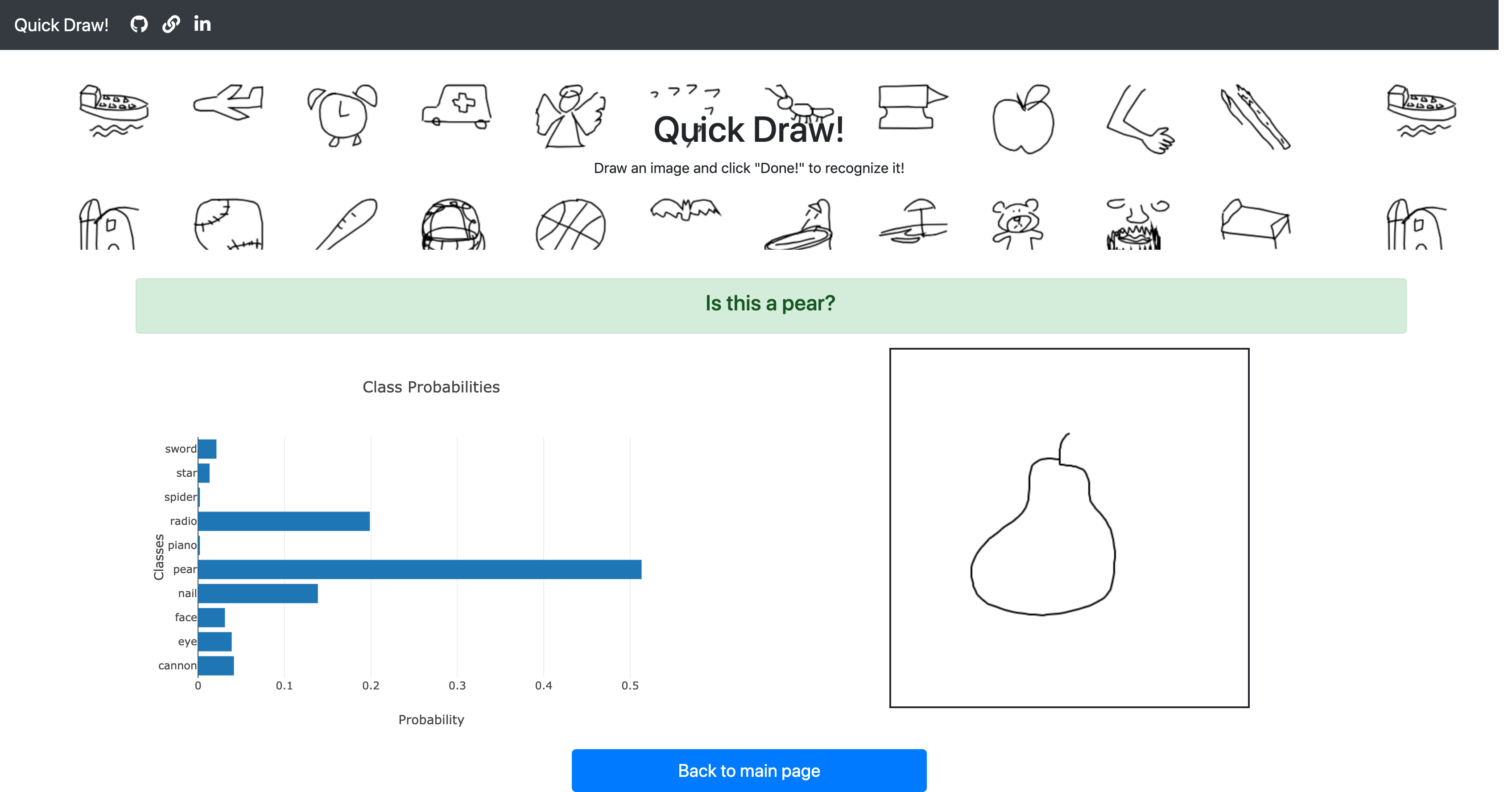
Research in recognition of images drawn by humans can improve pattern recognition solutions more broadly. Improving pattern recognition has an impact on handwriting recognition and its robust applications in areas including OCR (Optical Character Recognition), ASR (Automatic Speech Recognition) & NLP (Natural Language Processing). In this project, I analyzed the Quick, Draw! game drawings and built a deep learning application to classify those drawings.
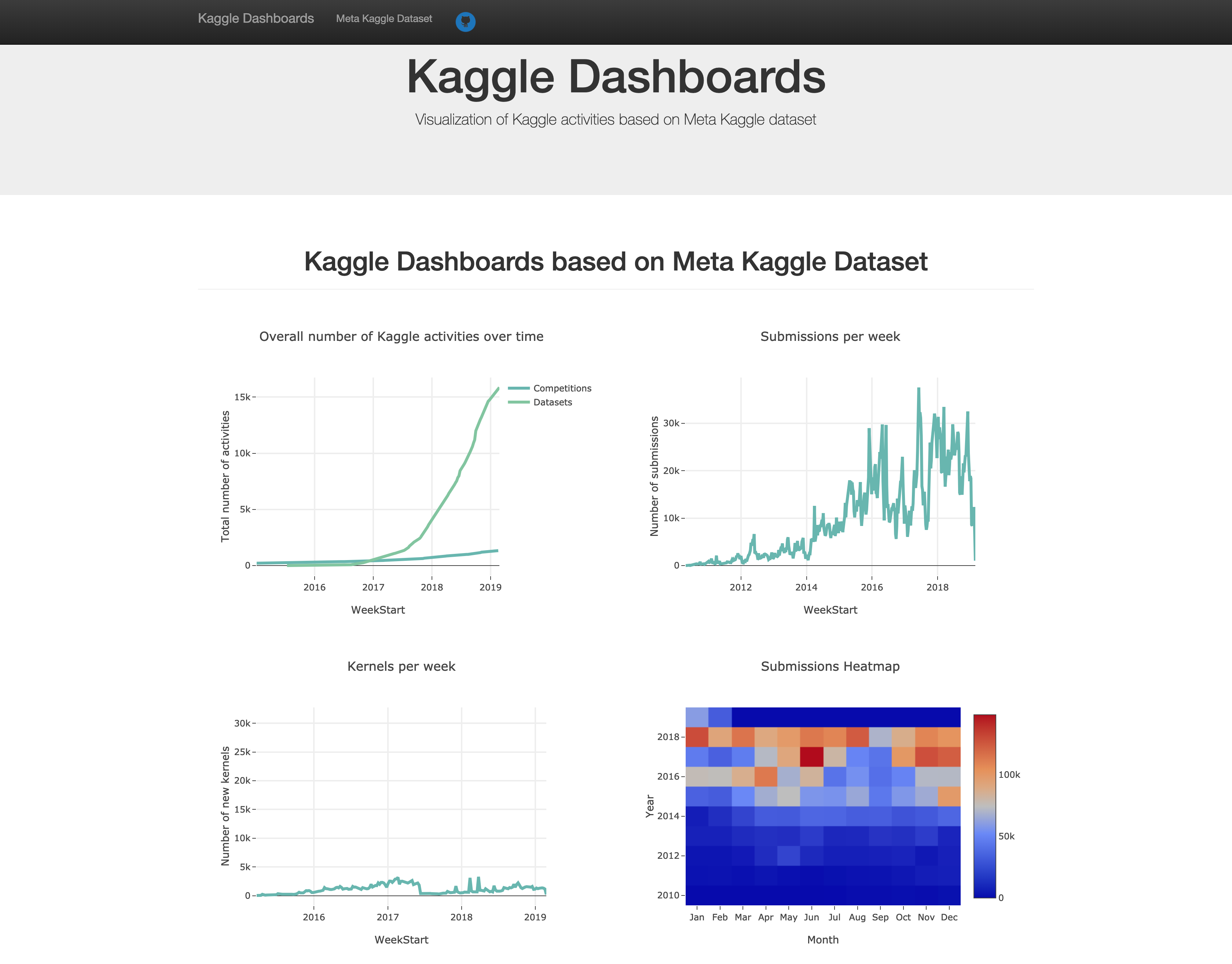
Flask web application to view dashboards demonstrating Kaggle activities. Data for dashboards is collected automatically using Kaggle API.
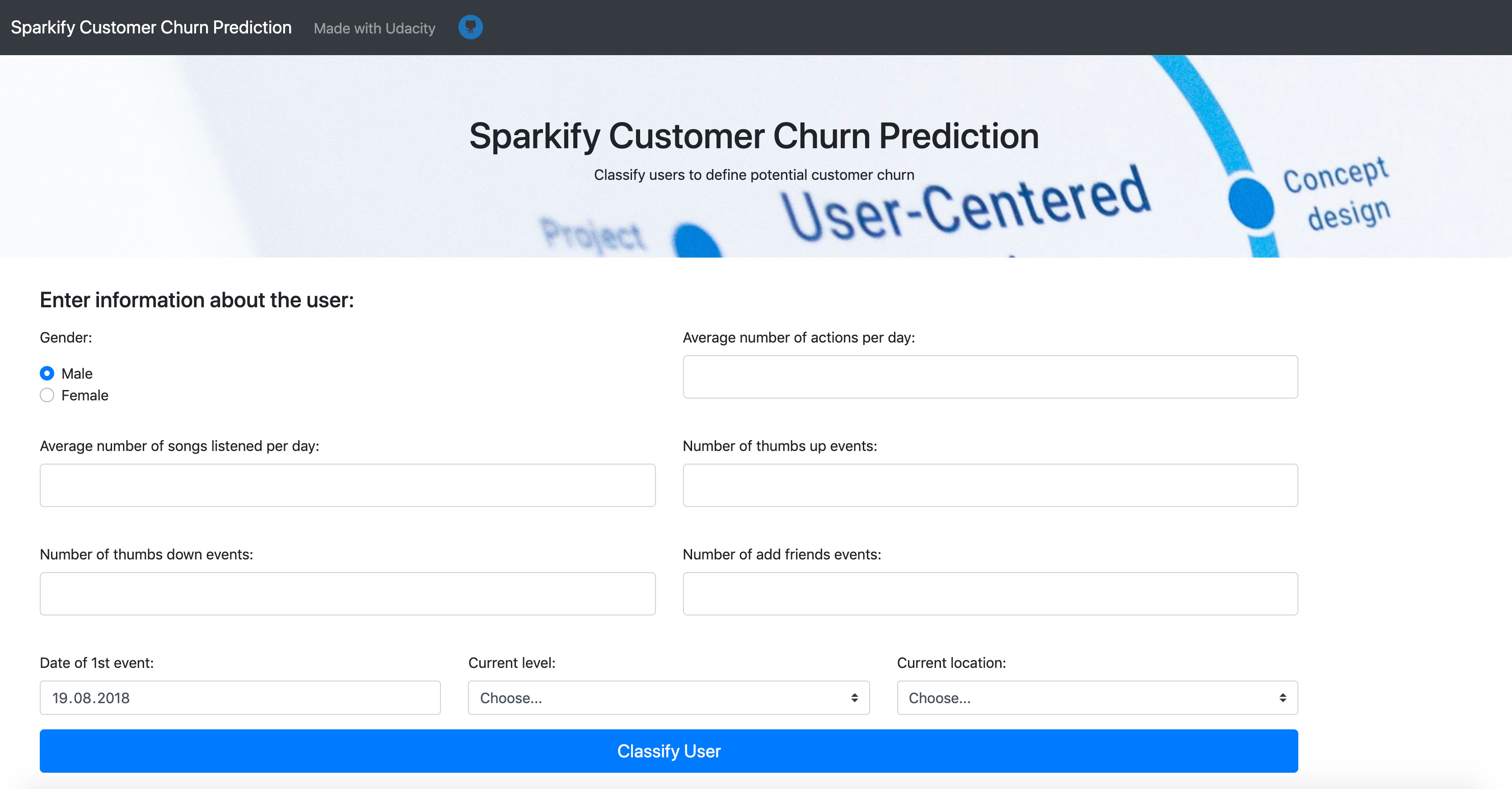
Predicting churn rates is a challenging and common problem that data scientists and analysts regularly encounter in any customer-facing business. It is crucial for businesses to identify customers who are about to churn and take action to retain them before it happens. The goal of this project was to help Sparkify music service retain their customers. In this project, I analyzed Sparkify data, built a machine learning model to predict churn and developed a web application to demonstrate the results.
I have recently joined Kaggle and started to create public kernels. My kernels have many views, but no upvotes. So I decided to analyze Meta Kaggle dataset to find out statistics for kernels, which obtained medals and how different factors affect the number of votes (for example, characteristics of the author, source dataset and so on)? Also, finally, make the recommendations on how to make the kernel useful so that other kagglers would cast upvotes.
When I first found out about sequence models, I was amazed by how easily we can apply them to a wide range of problems: text classification, text generation, music generation, machine translation, and others. I got an idea to use Meta Kaggle dataset to train a model to generate new kernel titles for Kaggle. Kernels are the notebooks in R or Python published on Kaggle by the users. Kaggle users can upvote kernels. Depending on the number of the upvotes, kernels receive medals. Model, which generates kernel titles, can help to capture trends for Kaggle kernels and serve as an inspiration for writing new kernels and get medals.
Mentoring Udacity Data Scientist Nanodegree students.
Performed business analysis, feature engineering, modelling, and review of machine learning pipelines for various projects:
Performed the analysis of financial data for building a data pipeline for real-time IFRS/MIS reporting. Analyzed over 700 attributes across various banking domains and designed the data processing pipeline.
Performed data analysis, conducted the data quality assessment (described the data quality metrics, data profiles, the rules for the data quality assessment):